A Linguagem de Programação C++
Qual o objetivo deste livro?
Este livro virtual gratuito é uma iniciativa da comunidade C/C++ Brasil que pretende trazer uma fonte moderna, confiável e completa para o estudo de C++. Sendo um livro da comunidade, você leitor também pode contribuir com correções e melhorias. Basta participar da nossa comunidade do Telegram e abrir um pull request no nosso repositório. Toda ajuda é bem vinda! :)
O que é C++?
C++ é uma linguagem de programação de propósito geral, compilada, estaticamente tipada, criada por Bjarne Stroustrup na década de 1980. A linguagem sofreu várias atualizações no decorrer dos anos, sendo C++20 a versão mais recente.
Ferramentas necessárias
Apesar de este livro focar no ensino de C++ moderno, é necessário se preocupar com algumas questões técnicas relacionadas ao ferramental. A princípio, é possível utilizar qualquer editor de texto ou IDE (Integrated Development Environment - Ambiente Integrado de Desenvolvimento) para escrever os códigos. É necessário ter em mãos algum compilador para traduzir o código-fonte para código executável. Existem diferentes implementações de compiladores para C++. Na maior parte dos casos, não há distinção de uso entre os compiladores. Nos raros casos onde isso não é verdade, este livro deixará claro no texto as eventuais diferenças.
Fica a cargo do leitor procurar e escolher as ferramentas de preferência para seguir com a leitura. Em ambiente Linux, os compiladores mais comuns são o GCC e o Clang. Em ambiente Windows, os compiladores mais comuns são o Microsoft Visual C++ e o Intel C++ Compiler.
Onde conseguir ajuda
Somos uma comunidade aberta e ativa no Telegram com mais de 700 membros. Novos membros são bem vindos para discussões técnicas sobre C/C++, bibliotecas e ferramentas relacionadas. Temos também nossa organização no Github, que conta com um repositório atualizado com fontes para material extra de aprendizado. Novos conteúdos são bem vindos, e podem ser sugeridos por meio de pull requests.
Capitulo 1: Um programa simples em C++
Olá mundo: Uma versão pragmática
O objetivo deste capítulo é introduzir vários conceitos básicos de programação C++ para iniciantes, ao mesmo tempo. Estes mesmos conceitos serão melhor elaborados mais pra frente. Iremos iniciar com o clássico código "Olá mundo", que segue abaixo. Apesar de simples, esse código tem muito a ensinar, como veremos. Copie o código abaixo para um arquivo de nome ola_mundo.cpp, e salve em algum diretório do seu sistema.
#include <iostream>
int main()
{
std::cout << "Olá Mundo!\n";
return 0;
}
Em primeiro lugar, a diretiva #include é a forma de incluir em nosso código as declarações necessárias para utilizar código externo. Ao incluir o header iostream, temos acesso à função cout, dentro do namespace std, que serve para escrever dados na tela durante a execução do programa. Seguindo, encontramos a função main. Essa função define o ponto de partida de qualquer programa C++. Dentro da função main, encontramos a instrução std::cout seguida da mensagem "Olá Mundo", que será mostrada na linha de comando. Por fim, temos o retorno da função main. É importante retornar o valor 0, que significa, por convenção, que o programa terminou com sucesso.
Para executar o programa, é preciso utilizar um programa chamado compilador (compiler), que executará um processo chamado compilação (compilation). Este processo é a tradução do código fonte para "código de máquina". No caso do C++, é a tradução do código escrito na linguagem para código executável por nossos computadores. Tente modificar o programa, trocando a mensagem, removendo partes do código e recompilando, verificando os erros que acontecem. Não tenha medo de errar e nem de gerar erros de compilação. Acredite, eles vão acontecer mesmo quando você estiver usando a linguagem com fluência.
Esta etapa é dependente do ambiente de trabalho que você está utilizando. Apenas para fins ilustrativos, os comandos abaixo mostram o processo de compilação em ambiente Linux, utilizando o GCC.
$ g++ -o ola_mundo ola_mundo.cpp
$ ./ola_mundo
Olá Mundo!
Olá mundo: Uma versão completa
Apesar do capítulo anterior ser suficiente para um primeiro contato com C++, talvez não fique claro outros aspectos ortogonais à linguagem, tais como escolhas de organização do código e do aspecto cultural do código. Desta forma, nosso primeiro projeto começa utilizando a linha de comando para instalar as ferramentas necessárias para a criação de um projeto. Os comandos aqui utilizados serão focados na command line interface (cli) do Unix. Caso você utilize Windows, o Mingw pode ser utilizado.
Configurações de ambiente
Nesta parte serão abordados os programas necessários para ter um "Olá mundo" funcional. O primeiro programa que precisamos instalar é o git - um sistema de versionamento de código. Seu propósito é manter um registro facilmente acessável das alterações feitas em um projeto, de modo que não precisemos perder tempo no futuro buscando informação sobre o código em e-mails, Google Docs ou pendrives (por exemplo). Iniciaremos um repositório git na pasta de projetos e iremos criar um projeto em C++ utilizando o CMake.
Se você utiliza:
- Mac
- Instale o
XCode Command Line Tools
- Instale o
- Windows
- vá em
www.git-scm.come baixe o instalador para Windows
- vá em
- Linux / BSD
- Utilize o gerenciador de pacotes da sua distribuição para instalar o git
- Debian, Ubuntu e derivados: apt
- Fedora e derivados: dnf
- openSUSE e derivados: zypper
- Arch e derivados: pacman
- Outras: Verifique na documentação de sua distribuição como fazer a instalação
- Utilize o gerenciador de pacotes da sua distribuição para instalar o git
Após ter o git instalado, precisamos abrir uma área para nosso projeto. Abra um terminal, ou prompt de comandos. No Linux você tem as opções de konsole, gnome-terminal, xterm, urxvt e muitos outros. No Windows o programa vem junto com a instalação do git. Já no Mac, o programa se chama terminal, mas você pode também instalar um substituto melhor chamado iterm2.
Este livro segue a seguinte notação:
- Linhas iniciando por
$: Usuário não-administrador - Linhas iniciando por
#: Usuário administrador ~: Pasta 'inicial' (home) do usuário
Alguns comandos básicos para o terminal:
pwd: Retorna o caminho da pasta em que você está nesse momentocd: Muda de pasta ("Change Directory")mkdir: Cria uma pasta ("Make Directory")touch: Cria um arquivols: Lista os arquivos da pasta atualtree: Exibe as pastas em forma de árvore
Sugere-se criar uma pasta de projetos dentro da pasta inicial do seu usuário, conforme exemplo:
$ mkdir Projetos
$ mkdir Projetos/OlaMundo
$ cd Projetos/OlaMundo
$ pwd
/home/user/Projetos/OlaMundo
Utiliza-se o git para criar um novo repositório dentro da pasta recém-criada (veja abaixo). Você pode verificar a existência de uma nova pasta chamada .git utilizando o comando ls. As opções -al servem para exibir arquivos ocultos (-a) e para exibir os arquivo em uma lista vertical (-l).
$ pwd
/home/user/Projetos/OlaMundo
$ git init .
Initialized empty Git repository in /home/user/Projetos/OlaMundo/.git/
$ ls -al
total 12
drwxr-xr-x 3 user user 4096 Nov 9 16:53 .
drwxr-xr-x 3 user user 4096 Nov 9 16:48 ..
drwxr-xr-x 7 user user 4096 Nov 9 16:51 .git
Neste momento, é importante iniciar uma estrutura básica de projeto, com arquivos que não necessariamente compõem o código-fonte. Mesmo sendo um código exemplo, algumas padronizações são importantes em qualquer código para que outros programadores saibam por onde começar a olhar o seu projeto. Crie o arquivo README.md (o nome README.md é reconhecido por diversas ferramentas de gerenciamento de código). O formato .md significa Markdown e é um formato de texto puro que tem alguma informação sobre a formatação do conteúdo.
$ touch README.md
$ ls -la
total 12
drwxr-xr-x 3 user user 4096 Nov 9 17:11 .
drwxr-xr-x 3 user user 4096 Nov 9 16:48 ..
drwxr-xr-x 7 user user 4096 Nov 9 17:01 .git
-rw-r--r-- 1 user user 0 Nov 9 17:11 README.md
Utilize algum "editor de texto pra programação" pra escrever algo no arquivo criado. Evite editores como Microsoft Word, Microsoft Office, LibreOffice ou Wordpad, pois esses não são editores de texto cru, e portanto não trabalham normalmente com arquivos de texto simples. Também evite editores de texto simples demais, como o Notepad (Bloco de notas). Alguns editores sugeridos:
O arquivo deve conter informações básicas do projeto, como seu titulo, uma breve descrição, autor, informações de como compilar o projeto, bibliotecas e ferramentas dependentes, e qualquer outras informações relevantes para outros desenvolvedores. Exemplo:
# Projeto: Olá mundo
Esse projeto serve como esboço do que é necessário para começar
a trabalhar com C++ no mundo real.
o # cria uma linha de cabeçalho, que é o título do arquivo, e parágrafos são espaçados com uma linha em branco. Este livro está sendo escrito em markdown, e o resultado final é o que você está lendo! Adicione o arquivo ao seu repositório:
$ pwd
/home/user/Projetos/OlaMundo
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
README.md
nothing added to commit but untracked files present (use "git add" to track)
Perceba a linha Untracked files:, essa é a lista de arquivos que o git ainda não está gerenciando. Precisamos adicionar o arquivo no índice de arquivos gerenciados pelo git:
$ pwd
/home/user/Projetos/OlaMundo
$ git add README.md
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: README.md
O comando executado não adicionou nada ao repositório, apenas adicionou o arquivo à Staging Area, que é a área onde os arquivos ficam preparados para serem adicionados em uma revisão. A seguir, commitamos o arquivo com uma mensagem descrevendo o que foi feito, da seguinte forma:
$ git commit -m "Adicionado arquivo Readme."
[master (root-commit) 478f2b6] Adicionado arquivo Readme.
1 file changed, 6 insertions(+)
create mode 100644 README.md
A configuração do projeto pode ser feita utilizando o CMake. O CMake é um gerenciador padrão para projetos em C++, e serve para traduzir as informações do código-fonte, a sua organização em arquivos, e quais subprojetos você está fazendo dentro de seu código, para as ferramentas da linguagem - como compiladores, depuradores (debuggers), IDEs. Assim, prepare um arquivo chamado CMakeLists.txt juntamente com uma pasta chamada src (source), onde ficará o código-fonte do projeto.
$ pwd
/home/user/Projetos/OlaMundo
$ touch CMakeLists.txt
$ mkdir src
$ touch src/main.cpp
$ touch src/CMakeLists.txt
O sistema de arquivos no momento é esse:
.
├── CMakeLists.txt
├── README.md
└── src
├── CMakeLists.txt
└── main.cpp
Perceba que existem 2 arquivos CMakeLists.txt. O que está na pasta raiz do projeto irá definir as configurações de base, e irá adicionar a pasta src no projeto. O conteúdo do arquivo na pasta raiz deve ser conforme segue:
cmake_minimum_required(VERSION 3.19)
project(OlaMundo CXX)
add_subdirectory(src)
Onde a primeira linha define a versão minima de CMake necessária para trabalhar com o projeto. A segunda linha especifica o nome do projeto para o CMake. A última linha adiciona a pasta src ao projeto. Nessa pasta, encontra-se outro arquivo CMakeLists.txt, contendo configurações de compilação.
add_executable(HelloWorld)
target_sources(
HelloWorld
PRIVATE
main.cpp
)
target_compile_features(
HelloWorld
PRIVATE
cxx_std_17
)
O comando add_executable determina que esse projeto irá gerar um executável HelloWorld. Esse executável será gerado a partir da compilação dos arquivos determinados em target_sources (ou seja, o arquivo main.cpp). Por fim, target_compile_features especifica as "features" necessárias para produzir o executável. No exemplo, utiliza-se a versão C++17 para a compilação do projeto. Sugere-se verificar a tabela encontrada no cppreference para verificar as features disponíveis em cada versão do C++, para os compiladores mais comuns. Por fim, o conteúdo do arquivo src/main.cpp é mostrado abaixo.
#include <iostream>
#include <cstdlib>
int main() {
std::cout << "Olá mundo!\n";
return EXIT_SUCCESS;
}
A única diferenca deste código para milhares de códigos de outros livros é a adição do header cstdlib para o EXIT_SUCCESS. cstdlib possui EXIT_SUCCESS e EXIT_FAILURE para indicar quando algo deu errado ou não, e mesmo que não modifique o funcionamento do código (EXIT_SUCCESS é definido como 0), é uma forma de explicitar o valor de retorno ao leitor.
Para determinar como o CMake irá configurar nossos projetos, é sugerido criar uma configuração base. A partir da versão 3.19, o CMake possui um comando --preset que utiliza uma configuração predeterminada. Crie um arquivo chamado CMakePresets.json, na pasta raiz do projeto:
{
"version": 1,
"cmakeMinimumRequired": {
"major": 3,
"minor": 19,
"patch": 0
},
"configurePresets": [
{
"name": "debug",
"displayName": "Compilacao Debug",
"description": "Compila em modo debug usando make",
"generator": "Unix Makefiles",
"binaryDir": "${sourceDir}/build/debug",
"cacheVariables": {
"CMAKE_BUILD_TYPE": "Debug"
}
},
{
"name": "release",
"displayName": "Compilacao Release",
"description": "Compila em modo release utilizando o Ninja",
"generator": "Ninja",
"binaryDir": "${sourceDir}/build/release",
"cacheVariables": {
"CMAKE_BUILD_TYPE": "Release"
}
}
]
}
Com essa configuração criamos dois geradores:
- Debug (Utilizando Unix Makefiles): A escolha do Unix Makefiles para o gerador de Debug é por ele ser sequencial, onde cada arquivo espera sua vez para ser compilado, facilitando a identificação de erros.
- Release (Utilizando Ninja): A escolha do Ninja para o gerador de Release possibilita uma compilação paralela, onde múltiplos arquivos são compilados ao mesmo tempo, tornando a compilação mais rápida.
Por fim, para configurar o projeto utilizando o preset escolhido:
$ pwd
/home/user/Projetos/OlaMundo
$ ls
CMakeLists.txt CMakePresets.json README.md src
$ cmake . --list-presets
Available presets:
"debug" - Compilacao Debug
"release" - Ninja
$ cmake . --preset=debug
Preset CMake variables:
CMAKE_BUILD_TYPE="Debug"
-- The C compiler identification is GNU 10.2.0
-- The CXX compiler identification is GNU 10.2.0
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /usr/bin/cc - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Configuring done
-- Generating done
-- Build files have been written to: /home/user/Projetos/helloworld/build/debug
A última linha indica onde os arquivos de build do projeto foram gerados. Esta se refere à linha definida em binaryDir no arquivo de preset. Para compilar o programa, deve-se executar cmake --build. Por exemplo, para compilar o projeto em debug:
$ cmake --build ./build/debug
Scanning dependencies of target HelloWorld
[ 50%] Building CXX object src/CMakeFiles/HelloWorld.dir/main.cpp.o
[100%] Linking CXX executable HelloWorld
[100%] Built target HelloWorld
O objetivo desse capítulo foi dar uma longa introdução ao C++ considerando várias ferramentas comuns em ambiente de trabalho profissional. Para maiores detalhes em relação às ferramentas, sugere-se buscar as documentação das mesmas, pois a explicação detalhada de cada uma foge do escopo desse livro.
Conceitos Básicos
Esse capítulo traz uma sequência inicial e básica de conteúdos para começar a fazer programas em C++.
Variáveis
Uma variável é um meio de armazenar valores e atribuir nomes a eles; de modo mais técnico, variáveis são um espaço de memória no seu computador usado para guardar informações, que podem ser de vários tipos: números, caracteres, texto, entre outros. Graças a isso, diz-se que C++ é uma linguagem de programação tipada.
Em C++, todas as variáveis possuem um tipo, e o tipo da variável não muda, até que ela deixe de existir (nos referimos a isso como o "tempo de vida", ou "lifetime", de uma variável). Diz-se então que C++ é uma linguagem de programação estaticamente tipada.
Variáveis são definidas da seguinte forma:
int main()
{
int some_int = 8;
// A variávei de nome some_int é do tipo inteiro (int) e possui o valor 8
float some_float = 9.2;
// A variávei de nome some_float é do tipo ponto flutuante (float) e possui o valor 9.2
char some_char = 'a';
// A variávei de nome some_int é do tipo caractere (char) e possui o valor 'a'
bool some_bool = true;
// A variávei de nome some_int é do tipo booleano (bool) e possui o valor true
return 0;
}
O tempo de vida de uma variável é delimitado por seu escopo. O escopo de uma variável é determinado pelo bloco que a contém, delimitado por chaves ({}). O exemplo anterior possui quatro variáveis, cada uma de um tipo diferente, e todas elas estão no escopo da função "main". Uma variável chega ao fim do seu tempo de vida ao final do escopo que a contém. Se uma variável está fora de qualquer escopo, ela é chamada de variável global.
Alternativamente, C++ moderno (do padrão C++11 em diante) traz uma sintaxe alternativa para definir o tipo das variáveis, por meio da palavra chave auto. Dessa forma, não é necessário explicitar o tipo das variáveis. Note que a variável ainda possui um tipo bem definido. A única diferença é que o tipo é determinado automaticamente em tempo de compilação (compile time), através de um processo chamado inferência:
int main()
{
auto some_int = 8;
auto some_float = 9.2;
auto some_char = 'a';
auto some_bool = true;
}
Em C++, o tipo string, para representar textos, não é um tipo primitivo. Para isso, existe o tipo std::string na biblioteca padrão do C++ (stdlib). Para utilizá-lo, é necessário incluir o header <string>, da mesma forma que incluímos <iostream> anteriormente para podermos escrever na tela.
#include <string>
int main()
{
std::string some_string = "First string";
// ... alternativamente, usando `auto`:
auto some_string_2 = std::string("Second string");
// ... ou, usando `auto` e `string literals`:
using namespace std::string_literals;
auto some_string_3 = "Third string"s; // Note o `s` após a string!
}
Note que um literal de texto entre aspas duplas como "my string" não é do tipo std::string.
Isto causa um pouco de confusão, e será melhor explicado adiante.
Por ora, mantenha em mente as formas de declarar vistas acima (perceba o sufixo "s" no terceiro caso utilizando auto!)
Instruções
Instruções em C++ são conceitos de alto nível (isto é, conceitos simples de serem entendidos por humanos) e servem para dividir a execução do código em etapas. Elas não devem ser confundidas com as instruções de um processador, que são de baixo nível (mais difícil de entender por humanos, porém fácil para uma máquina executar).
Existem vários tipos de instruções, as mais comuns sendo as instruções de expressão (expression statements). Instruções de expressão, também chamadas expressões, são operações básicas como x + 2, a + 5 * 3 e pi = atan(i) * 4, seguidas de um ;. Ao declarar variáveis, nós utilizamos instruções de declaração (declaration statements), também chamadas declarações.
Instruções compostas
Saber diferenciar todos os tipos de instrução é raramente necessário, mas as instruções compostas (compound statements) merecem atenção. Instruções compostas agrupam zero ou mais instruções em uma só.
O corpo de uma função comum, que veremos mais adiante, é uma instrução composta contendo quatro instruç:
int main()
{ // Início da instrução composta
int x = 2;
int y = 3;
int z = x + y;
return 0;
} // Fim da instrução composta
Você verá, mais pra frente, muitos outros casos em que há a necessidade de utilizar esse tipo de instrução.
Estruturas de controle
A estrutura "if" / "else if" / "else"
Estruturas de controle (control structures, control flow) são construções da linguagem que nos permitem fazer coisas mais complexas do que apenas executar instruções de maneira sequencial. A primeira que veremos é a estrutura if/else if/else. Ela nos permite tomar decisões e executar instruções diferentes dada uma ou mais condições. No exemplo abaixo, temos um programa simples que informa o preço que um cliente deve pagar em um cinema onde:
- Clientes abaixo de 10 anos de idade não pagam.
- Clientes acima de 50 anos pagam meia-entrada.
- Demais clientes pagam o valor normal da entrada.
#include <iostream>
int main()
{
int age = 0;
double const price = 20.0;
std::cout << "Insira sua idade: ";
std::cin >> age;
std::cout << "Sua idade é " << age << '\n';
if (age <= 10) {
std::cout << "Você não precisa pagar!\n";
} else if (age > 50) {
std::cout << "Você paga apenas " << price/2 << "!\n";
} else {
std::cout << "Você paga " << price << ".\n";
}
}
O exemplo acima introduz também uma forma de ler dados de entrada (input) providenciados pelo usuário. Note que a variável age é inicializada com o valor 0. Porém, a linha std::cin >> age; permite ao usuário que estiver executando o programa informar um novo valor para age. Desta forma, o valor de age que será utilizado pelo programa será conhecido apenas durante a execução.
No exemplo, a linha 10 sempre será executada depois que o usuário informar o valor de age. Porém, a linha 13 será executada apenas se (if) a variável age tiver um valor abaixo de 10. A construção else if permite fazer um novo teste caso o teste anterior falhe, ou seja, a condição não seja verdadeira. Por outro lado, utilizar apenas else faz com que, caso nenhuma das condições anteriores tenha sido satisfeita, o código dentro do bloco seguinte execute garantidamente. Experimente alterar o valor de age para fazer com que o programa siga cada uma das possibilidades.
As estruturas while e for
As estruturas de controle while e for servem para repetir um bloco de código até que uma condição seja satisfeita. Este tipo específico de estrutura de controle se chama laço (loop). No exemplo abaixo, o programa pergunta se o usuário deseja aprender C++. Enquanto (while) a resposta não for s (sim) nem n (não), a mesma pergunta aparecerá para o usuário. Uma vez que o usuário der uma resposta válida, um if imprime a reação correspondente à resposta do usuário.
#include <iostream>
int main()
{
char answer = '\0';
while (answer != 's' && answer != 'n') {
std::cout << "Você deseja aprender C++? [s/n]: ";
std::cin >> answer;
}
if (answer == 's') {
std::cout << "Esse é o espírito!\n";
} else {
std::cout << "Que triste...\n";
}
}
Em geral, usamos o laço while quando não existe uma definição clara de quantas vezes precisamos rodar o laço, apenas uma condição de continuidade que deve em algum momento posterior tornar-se falsa.
O laço for adiciona legibilidade ao código quando temos uma inicialização e um passo que deve ser executado em toda iteração do laço. Tudo que é feito com um laço for pode também ser feito com um laço while, e vice versa. A diferença entre eles é que, em alguns casos, a leitura do código fica mais natural com um ou com outro. Ao contrário do while, o for se presta mais quando sabemos exatamente quantas vezes precisamos repetir as operações. No código abaixo, o laço for itera com valores de i = a até valor de i = b, somando 1 ao valor de i a cada iteração. Uma forma alternativa e mais compacta de escrever i = i + 1 seria escrever ++i.
#include <iostream>
int main()
{
int a = 0;
int b = 0;
std::cout << "Digite o valor de A: ";
std::cin >> a;
std::cout << "Digite o valor de B: ";
std::cin >> b;
int sum = 0;
for (int i = a; i <= b; i = i + 1) {
sum += i;
}
std::cout << "Sum [" << a << ", " << b << "] = " << sum << std::endl;
return 0;
}
As instruções continue e break
Quando utilizamos um laço, é possível que queiramos interrompê-lo prematuramente. Para isso existe a instrução break:
#include <iostream>
int main()
{
for (int i = 1; i <= 100; i = i + 1) {
std::cout << "Iteração #" << i << '\n'
<< "Você deseja continuar? [s/n]: ";
char op;
std::cin >> op;
if (op == 'n')
break;
std::cout << "Incrementando i..." << std::endl;
}
return 0;
}
Assim que a execução do programa atinge a instrução break, o laço é imediatamente interrompido; o i deixa de ser incrementado e vamos direto para nosso return.
Caso queiramos interromper a execução do corpo (a instrução composta, delimitada por chaves) de nosso laço mas continuar iterando, devemos utilizar a instrução continue:
#include <iostream>
int main()
{
for (int i = 1; i <= 100; i = i + 1) {
std::cout << "Iteração #" << i << '\n'
<< "Você deseja pular essa iteração? [s/n]: ";
char op;
std::cin >> op;
if (op == 's')
continue;
std::cout << "Executando o resto do corpo do laço" << std::endl;
}
return 0;
}
Perceba que, como i = i + 1 não faz parte do corpo do laço, ele é executado independentemente do continue. Lembre-se que isso não se aplica ao break.
É possível que você não veja vantagens imediatas no uso dessas duas instruções, mas elas podem simplificar o código e às vezes são até necessárias.
Devo utilizar { e }?
Você pode ter percebido que o corpo das instruções if (e suas partes else), for e while podem ser tanto uma instrução simples quanto uma instrução composta. Quando estas estruturas de controle consistem apenas de uma instrução, não é obrigatório utilizar chaves. Por exemplo, os dois if seguintes são equivalentes:
if (a) {
b = 5;
}
if (a)
b = 5;
Agora, quando precisamos de mais de uma instrução, precisamos agrupá-las como uma só:
if (a) {
b = 5;
c = 6;
} // Ok! Ambas as atribuições fazem parte do if
if (a)
b = 5;
c = 6; // Ops! Essa instrução não faz parte do if
Alguns programadores optam por utilizar sempre instruções compostas para evitar surpresas. Há bons argumentos tanto a favor quanto contra isso, portanto ao trabalhar em um projeto preexistente siga o padrão de estilo que já esteja sendo utilizado.
Funções
Para deixar partes do programa reutilizáveis, e para adicionar legibilidade ao código, utilizamos funções. Funções são pedaços de código que são definidas uma vez em um lugar, mas que podem ser reutilizadas quantas vezes quiser em outros lugares do código.
Elas servem para que não precisemos reescrever o mesmo código múltiplas vezes, e permitem que sigamos o princípio do Não Se Repita (Don't repeat yourself - DRY).
Funções podem ou não receber parâmetros, que são usados para levar informações de um escopo para outro. Os parâmetros são, por padrão, cópias das variáveis que são levadas ao escopo da função invocada, e eles aparecem entre parênteses após o nome da função, separados por vírgula.
Funções possuem também um valor de retorno, que possibilita capturar uma variável concebida dentro do escopo da função para o local onde ela foi chamada. Abaixo um exemplo de função:
#include <iostream>
int calculate_sum(int a, int b)
{
int sum = 0;
for (int i = a; i <= b; ++i) {
sum += i;
}
return sum;
}
int main()
{
int a = 0;
int b = 0;
std::cout << "Digite o valor de A: ";
std::cin >> a;
std::cout << "Digite o valor de B: ";
std::cin >> b;
std::cout << "Sum [" << a << ", " << b << "] = " << calculate_sum(a, b) << std::endl;
return 0;
}
No código acima, foi definida uma função calculate_sum, que necessita de dois parâmetros do tipo int a e b, e que efetua a soma dos valores de a a b, e retorna essa soma (por exemplo, se a for 2 e b for 5, a soma será 2 + 3 + 4 + 5, e o valor retornado será 14). O tipo de retorno de uma função é determinado em sua assinatura. A assinatura de uma função é o conjunto contendo seu nome, seu tipo e seus parâmetros, por exemplo, int calculate_sum(int a, int b).
As funções devem ser pelo menos declaradas antes de serem utilizadas. Por exemplo, se movermos a definição da função calculate_sum para baixo da função main, teriamos um erro de compilação. Existe uma distinção entre declarar uma função e definir uma função. Declarar uma função é apenas mostrar que ela existe, sem determinar seu funcionamento (ou seja, sem adicionar o corpo de código dela). Definir uma função é adicionar um corpo de código a uma declaração.
No exemplo acima, estamos definindo a função calculate_sum. Um exemplo de separação entre a declaração e a definição de função é mostrado abaixo.
#include <iostream>
// Declaração da função `calculate_sum`
int calculate_sum(int a, int b);
int main()
{
int a = 0;
int b = 0;
std::cout << "Digite o valor de A: ";
std::cin >> a;
std::cout << "Digite o valor de B: ";
std::cin >> b;
std::cout << "Sum [" << a << ", " << b << "] = " << calculate_sum(a, b) << std::endl;
return 0;
}
// Definição da função `calculate_sum`
int calculate_sum(int a, int b)
{
int sum = 0;
for (int i = a; i <= b; ++i) {
sum += i;
}
return sum;
}
Caso a função não retorne nenhum valor, é possível utilizar a palavra reservada void, conforme exemplo abaixo. Funções com tipo de retorno void podem (opcionalmente) omitir a chamada return, indicando o término da função. Enquanto funções com retornos específicos são particularmente úteis para obter o resultado de uma operação para que façamos algo com ele, funções do tipo void são particularmente úteis para executar uma ação. No exemplo anterior, queríamos obter um resultado, um número que representa uma soma, e fizemos algo mais com ele em main(). No exemplo seguinte, a única ação sendo executada é printar na tela o texto "Olá Mundo!", e não queremos fazer nenhuma operação com este texto depois que a função é executada.
void say_hello()
{
std::cout << "Olá Mundo!" << std::endl;
// Opcional:
// return
}
Tipos definidos pelo usuário
Structs (estruturas) são uma forma de adicionar tipos novos ao programa (user-defined types). Eles fornecem mais semântica a grupos de variáveis que se relacionam de alguma forma, agrupando múltiplas propriedades para que sejam usadas de uma vez.
No exemplo abaixo, uma estrutura de nome Point é definida entre as linhas 4 e 7. Ela possui dois membros: x e y, ambos do tipo primitivo double. Essas linhas definem um novo tipo de dado de nome Point, que pode ser utilizado em qualquer lugar do programa. As linhas 16 e 17 criam duas instâncias de duas variáveis com o novo tipo Point.
#include <iostream>
#include <cmath>
struct Point {
double x;
double y;
};
double calculate_distance(Point p1, Point p2)
{
return sqrt(pow(p1.x - p2.x, 2) + pow(p1.y - p2.y, 2));
}
int main()
{
Point p1{1.1, 2.7};
Point p2{3.7, 4.4};
std::cout << "A distância entre os pontos p1 e p2 é " << calculate_distance(p1, p2) << std::endl;
return 0;
}
Assim como qualquer outro tipo de variável, é possível utilizar o tipo Point como parâmetro para funções, como é o caso do exemplo acima, na linha 9.
A função calculate_distance necessita de dois parâmetros, p1 e p2, ambos do tipo Point para ser invocada. Note que, ao invocar a função na linha 19, as duas variáveis p1 e p2 são copiadas para o escopo da função calculate_distance. Ou seja, se alterarmos os valores de p1 e p2 dentro do corpo da função calculate_distance, os valores de p1 e p2 presentes no escopo da função main não serão alteradas.
Note que, por Point ser um tipo como qualquer outro, é possível compor estruturas aninhadas. Por exemplo, considere o seguinte problema:
Você está desenvolvendo um jogo de plataforma, e precisa representar o personagem em um espaço bidimensional. O personagem possui uma
posição e um número de vidas. Utilizando a estrutura anterior para representar a posição, poderia-se escrever:
using Life = unsigned int;
struct Player {
Point position;
Life life;
};
Como exemplo ilustrativo, utiliza-se aqui a palavra reservada using para criar um type alias (um "apelido" para um tipo qualquer).
Basicamente, dá-se um novo nome para um tipo que já existe. No exemplo acima, Life será equivalente ao tipo unsigned int, ou seja, um inteiro não negativo. Deste modo, toda vez que usarmos o tipo Life, estaremos criando, por trás dos panos, um unsigned int.
Outro modo de criarmos tipos definidos pelo usuário é por meio de classes, que veremos mais à frente.
Referências
Referências permitem criar "apelidos" para variáveis, isto é, uma referência para uma variável acessa o valor daquela variável, nomeada de outra forma. Considere o código abaixo, onde é criada uma referência de nome b para uma variável de nome a. Utiliza-se o simbolo & junto ao tipo da variável para declarar uma referência. Diferente de uma variável "comum", alterar o valor da referência altera o valor da variável referenciada. Portanto, no exemplo abaixo, o resultado vai ser a mensagem a = 7, b = 7.
#include <iostream>
int main()
{
int a = 1;
int& b = a;
// Já que a variável 'b' se refere a 'a',
b = 7;
// então atribuir '7' para 'b' significa atribuir '7' para 'a'.
std::cout << "a = " << a << ", b = " << b << std::endl;
return 0;
}
Como uma referência é um "apelido" para outra variável, é impossível criar uma referência para um valor. Por exemplo, int& b = 9; não faz sentido, e ocasiona em um erro de compilação.
É possível usar referências também na passagem de parâmetros de funções. Quando não são utilizadas referências nos parâmetros de uma função, as variáveis são copiadas para o escopo da função. Referências passadas por parâmetro e modificadas dentro do escopo de uma função alteram o valor da variável original de onde foi chamada, como mostra o exemplo abaixo.
#include <iostream>
void wont_change_data(int a)
{
a = 1;
}
void will_change_data(int& a)
{
a = 1;
}
int main()
{
int my_a = 8;
std::cout << my_a << std::endl;
// Saída: 8
wont_change_data(my_a);
std::cout << my_a << std::endl;
// Saída: 8
will_change_data(my_a);
std::cout << my_a << std::endl;
// Saída: 1
}
Outro exemplo pode observado no código abaixo. Imagine que Matrix é uma estrutura de dados que representa uma matriz 100x100. A função sum_elements soma todos os elementos dessa matriz.
O loop na função main foi criado sinteticamente para representar muitas chamadas da função sum_elements. Para cada invocação da função sum_elements, uma instância da estrutura de dados Matrix é copiada para o contexto da função, apenas para somar o valor de cada um de seus elementos.
/**
* Soma dos elementos de uma matriz 100x100
* :param Matrix matrix:
* :returns double:
*/
double sum_elements(Matrix matrix)
{
double sum = 0.;
for (int i = 0; i < 100; ++i) {
for (int j = 0; j < 100; ++j) {
sum += matrix[i][j];
}
}
return sum;
}
int main()
{
// ...
double total_sum = 0.;
for (int i = 0; i < 1000000; ++i) {
total_sum += sum_elements(matrix);
}
std::cout << "Total Sum = " << total_sum << std::endl;
return 0;
}
Uma forma de evitar a cópia dessa estrutura de dados é utilizando uma referência para uma Matrix, ou seja, trocando a assinatura da função para double sum_elements(Matrix& matrix). Apesar de resolver o problema das cópias desnecessárias, a solução mencionada não é ideal, pois passando uma referência à estrutura Matrix, os dados da estrutura podem ser modificados dentro do escopo da função.
Normalmente, é interessante evitar funções com esse tipo de "efeito colateral" ("side effects"), pois à medida que o projeto cresce, isso pode gerar um problema de manutenibilidade. Para ter noção do quanto essas cópias fazem diferença nesse caso, considere a comparação abaixo, extraída a partir de benchmark feito no site Quick Bench.
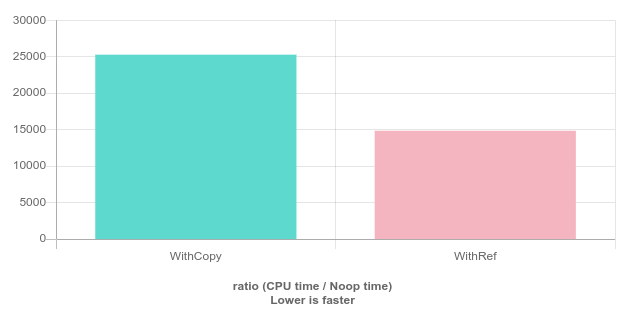
Existem sim alguns programas que usam referências como parâmetros de funções e modificam seus dados. Não há problemas em fazer isso, desde que seja bem documentado ou seja óbvio ao leitor. Por exemplo, no caso acima, não é esperado que uma função de nome sum_elements altere os elemento da matriz, porém uma função chamada void sum_one_to_all_elements_in(Matrix& m) deixa mais claro que todos os elementos da matriz serão alterados.
Uma alternativa para evitar o problema comentado é o uso do modificador const, que faz com que a "variável" em questão seja constante, ou seja, não possa ser alterada durante a execução do programa. Antes de partir para seu uso no caso da função sum_elements, considere o uso de const em um exemplo mais simples:
#include <iostream>
int main()
{
double const a = 8;
a = 9; // Erro de compilação
}
O código acima não irá compilar. Isso porque a variável "a" é uma constante, ou seja, não se pode alterar seu valor, como se está tentando fazer na linha 6. Casos comuns de uso de const são, por exemplo, as variáveis matemáticas PI e e. O modificador const pode também ser utilizado em conjunto com referências, criando-se referências constantes, ou seja, não é possível alterar o valor da variável referenciada.
#include <iostream>
int main()
{
double a = 8;
double const& b = a;
a = 9; // OK. `a` não é `const`. (b também assume o valor `9`)
b = 7; // Erro de compilação: `b` é uma referência const
}
O código acima não irá compilar. O motivo é que não se pode alterar o valor de "a" por meio da referência "b", pois ela é uma referência const. Um detalhe importante a se comentar é que o modificador const se aplica sempre ao tipo à sua esquerda. Se não houver nada à esquerda, ele se aplica ao tipo à direita. Dessa forma temos:
double const& my_data: Cria uma referência para umconst doubleconst double& my_data: Cria uma referência para umconst double(Igual à anterior)double &const my_data: Erro de compilação, pois não faz sentido ter uma "referência const", visto que referências não são modificáveis
Por fim, voltando ao problema da matriz, quando escrevemos double sum_elements(Matrix& matrix), evitamos que a matriz seja copiada, e isso é um ponto positivo, em termos de performance. Porém, introduzimos um possível problema: se a matriz for modificada dentro do escopo da função sum_elements, então a matriz do escopo da função main também será modificada.
Por convenção, não esperamos que ninguém vá de fato modificar os elementos da matriz naquela função. É possível garantir isso utilizando const&, isto é, se alguém por engano alterar a variável matrix de dentro da função sum_elements, um erro de compilação ocorrerá. A assinatura da função fica da seguinte forma: double sum_elements(Matrix const& matrix), e nenhuma outra modificação é necessária.
Ponteiros e smart pointers
Quando definimos uma variável em um programa C++, ela é alocada em uma posição de memória do computador. Um "endereço" é a localização em memória virtual de uma variável.
Apenas para fins ilustrativos, imagine que toda a memória do seu computador é uma grande tabela. Cada item da tabela possui um endereço e um valor, como no exemplo abaixo. O código de exemplo captura o endereço da variável a e o coloca como valor da variável b: A linha 6 cria a variável b, do tipo int*, e inicializa essa variável com o endereço de memória da variável a.
#include <iostream>
int main()
{
int a = 1;
int* b = &a;
std::cout << b << std::endl;
return 0;
}
| Endereço | Valor | Variável associada |
|--- |--- |--- |
| 0x7ff0 | 1 | a |
| 0x7ff4 | 0x7ff0 | b |
Os endereços na tabela estão em hexadecimal, pois é a forma comum de representar endereços de memória. São valores meramente ilustrativos, de forma que, caso você execute o programa no seu computador, irá ter resultados diferentes.
Apesar do uso do mesmo simbolo (&), nesse caso &a não é uma referência. Essa distinção é importante: Caso & esteja ao lado de um tipo (int, double, Point, etc...) tem-se uma referência. Por outro lado, caso & esteja ao lado do nome de uma variável (como no caso acima), lê-se "endereço de..." (no exemplo, "endereço de a").
O operador * aplicado a uma variável cujo tipo é um ponteiro, retorna o valor apontado por aquela variável, da seguinte forma:
#include <iostream>
int main()
{
int a = 1;
int* b = &a;
*b = 9;
std::cout << a << std::endl;
// Saída: 9
std::cout << b << std::endl;
// Saída: um endereço de memória (como 0x7ffcf973efb8 por exemplo)
std::cout << *b << std::endl;
// Saída: 9
return 0;
}
As variáveis criadas até agora nos exemplos desse livro são todas criadas numa região de memória denominada stack. O gerenciamento dessa memória é feito automaticamente, ou seja, as variáveis são criadas e alocadas na região da stack ao entrar em determinado escopo e, ao sair do mesmo, as variáveis são automaticamente removidas.
Outra forma de alocar memória é por meio das funções malloc e new. No geral, malloc é o jeito antigo de gerenciar memória, herdado do C. Em C++, sugere-se sempre utilizar new para alocação dinâmica de memória, ao invés de malloc, pois para instâncias de classes o new chama o construtor, fazendo a inicialização da variável, como será visto em capitulos posteriores.
Variáveis alocadas com new e malloc são colocadas em uma região de memória denominada heap. Diferente da stack, essas variáveis não são removidas automaticamente ao saírem do escopo corrente. O gerenciamento do tempo de vida desse tipo de variável deve ser feito pelo programador. O programador deve devolver a memória ao sistema operacional após término de uso da variável por meio da função delete, como no exemplo abaixo:
#include <iostream>
int main()
{
int* a = new int(3);
std::cout << "a = " << *a << std::endl;
delete a;
return 0;
}
A linha 5 faz a alocação dinâmica de uma variável do tipo int, inicializada com valor 3, e atribui o endereço dessa variável alocada para a variável a de tipo int*. A linha 6 mostra o valor apontado por a. A linha 7 deleta (devolve) a memória alocada na linha 5. Não deve-se utilizar uma variável depois que foi deletada. No caso de sistemas operacionais de propósito geral, como Windows e Linux, toda a memória alocada que não foi deletada é automaticamente devolvida no momento que o programa termina.
Gerenciar memória da heap não é um problema trivial. O mau gerenciamento da memória pode ocasionar em uma excessiva utilização da memória RAM, como é o caso dos vazamentos de memória (memory leaks), que é quando o programador "esquece" de devolver a memória.
Smart pointers são estruturas de dados que auxiliam no gerenciamento de dados alocados na heap. Basicamente, a estrutura aloca a variável na heap e, ao não ser mais utilizada, a remove automaticamente. De um modo geral, é boa prática de C++ utilizar smart pointers em abundância.
O exemplo abaixo é trivial, e apenas mostra o funcionamento da infraestrutura, mas não consegue captar por completo o valor de usar smart pointers. O uso de ponteiros e alocação dinâmica é especialmente relevante nos casos de interfaceamento com bibliotecas de baixo nível (por exemplo, funções C), ou no caso de uso de polimorfismo em programação orientada a objetos em C++, tema que será discutido posteriormente nesse livro.
#include <iostream>
#include <memory>
int main()
{
auto a = std::make_unique<int>(7);
std::cout << "a = " << *a << std::endl;
// A variável `a` será deletada automaticamente quando o escopo terminar
}
const, constexpr e consteval
Conforme apresentado no capítulo 2.6, o modificador const pode ser utilizado para criar constantes (variáveis com acesso apenas de leitura). Alterar uma variável que contém o modificador const causa um erro de compilação:
int main()
{
const int i = 10;
i = 11; // Erro de compilação: Atribuição à uma variável somente-leitura
return 0;
}
Este capítulo apresenta a diferença entre os modificadores const, constexpr e consteval, considerando seu uso em relação à variáveis e funções. O uso do modificador constinit e do modificador const em relação a métodos de classes será abordado apenas em capítulos posteriores.
Para compreender a diferença entre os modificadores, considere o seguinte código:
#include <iostream>
int sum(int a, int b) // Case (a)
// constexpr int sum(int a, int b) // Caso (b)
{
int c = a + b;
return c;
}
int main()
{
const int a = 1;
// int a = 1; // Caso (c)
int x = sum(a, 2);
std::cout << x;
}
Ao invocar a função sum, a soma dos valores a e b será computada. Esse calculo será feito em tempo de execução (runtime). Isso significa que a soma será efetuada apenas quando o usuário executar o programa. Por outro lado, ao utilizar constexpr (introduzido no C++11) na função sum, a função potencialmente será executada em tempo de compilação (compile time), ou seja, o valor de x talvez seja computado no momento de compilação do programa, caso as informações necessárias para tal estejam disponíveis.
Para compreender esse processo, é importante lembrar que todo código C++ é compilado, gerando um arquivo binário que contém o código de máquina. Esse arquivo binário contém instruções em linguagem de baixo nível específicas para cada processador. Mostra-se abaixo uma comparação de dois trechos de código de baixo nível gerados pelo exemplo anterior para o caso (a) sem o uso de constexpr e para o caso (b) com o uso de constexpr:
a) Sem o uso de constexpr:
mov esi, 2
mov edi, 1
call sum(int, int)
mov DWORD PTR [rbp-8], eax
b) Com o uso de constexpr:
mov DWORD PTR [rbp-8], 3
Não se preocupe caso não compreenda totalmente os códigos de máquina apresentados acima; trata-se de uma linguagem chamada assembly, extremamente próxima da linguagem de máquina. O código assembly está sendo usado apenas para ilustrar a diferença de código gerado: menos linhas aqui significa código mais eficiente. No caso (a), a linha call sum(int, int) mostra que a função sum será de fato invocada em tempo de execução. Já no caso (b), uma única linha é gerada, contendo o resultado (3) que foi, portanto, calculado em tempo de compilação e por isso aparece diretamente no código gerado.
É importante notar que constexpr só será executado em tempo de compilação caso seja possível conhecer todos os dados necessários para sua execução. Ainda no exemplo, considerando o caso (c), nota-se que utilizar uma variável não-const em uma função contendo o modificador constexpr ocasionará no seguinte código de máquina gerado:
c) Com uso de constexpr, porém, a variável a não é const
mov DWORD PTR [rbp-4], 1
mov eax, DWORD PTR [rbp-4]
mov esi, 2
mov edi, eax
call sum(int, int)
mov DWORD PTR [rbp-8], eax
Uma forma de evitar que uma função constexpr gere valores em tempo de execução inesperadamente, é utilizar consteval (a partir do C++20). Diferente de constexpr, consteval ocasiona em um erro de compilação caso não consiga processar a função em tempo de compilação. Por exemplo:
#include <iostream>
consteval int sum(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
// int a = 1; // Caso (a), gera erro de compilação
constexpr int a = 1; // Caso (b)
// const int a = 1; // Caso (c)
int x = sum(a, 2);
std::cout << x;
}
No exemplo acima, o caso (a) ocasionará em um erro de compilação. Os casos (b) e (c) geram o valor da variável x em tempo de compilação garantidamente. Note que, apesar dos casos (b) e (c) produzirem o mesmo código nesse caso, o uso de const e de constexpr não é equivalente, como será visto a seguir.
Basicamente, o modificador const aplicado a uma variável declara que aquela variável não será modificada em tempo de execução. O modificador constexpr aplicado a uma variável declara que aquela variável será computada em tempo de compilação e não será modificada em tempo de execução. Dessa forma, o caso (a) abaixo irá compilar normalmente, pois a variável a irá conter uma cópia constante da variável var, em tempo de execução. Já o caso (b) não irá compilar, pois a variável a não pode ser processada em tempo de compilação, visto que a variável var poderia ter sido modificada em algum momento no código.
int main()
{
int var = 1;
const int a = var; // Caso (a)
// constexpr int a = var; // Caso (b)
}
Namespaces
Considere o seguinte cenário: você está ajudando no desenvolvimento de um software de um painel digital para uma loja. O painel mostra mensagens de promoções primárias da loja e, agora, deseja-se adicionar um painel secundário para exibir promoções secundárias. Você foi designado a implementar uma função que toma como parâmetro uma mensagem e a mostra no display do novo painel. Para tal, você começa a escrever o código:
void write(std::string const& message)
{
// ...
}
Para sua surpresa, já existe uma outra função com exatamente a mesma assinatura, e você recebe o seguinte erro de
compilação: error: redefinition of 'void write(string)'. De fato, existe um problema de ambiguidade: Ambas as funções
foram criadas para o mesmo propósito: escrever uma mensagem em um display. Porém, o display em questão é diferente
dependendo do contexto. Existem várias maneiras de resolver tal problema. Uma possibilidade é dividir as implementações
em namespaces diferentes.
Um namespace é uma estrutura que pode conter classes, funções e variáveis. Eles não servem apenas para desambiguar
uma função ou classe, mas também para organizar o projeto. Eles são estruturas opcionais, e não é raro encontrar
bibliotecas e aplicativos escritos em C++ que são implementados sem o uso de namespaces.
Para resolver o problema comentado, poderia-se escrever o código anterior da seguinte forma:
namespace main_display {
void write(std::string const& message)
{
// ... Implementação do display principal
}
}
namespace secondary_display {
void write(std::string const& message)
{
// ... Implementação do display secundário
}
}
Para usar uma ou outra implementação, é necessário explicitar o namespace ao chamar a função, da seguinte forma:
main_display::write("...exemplo...");. Um código de exemplo é mostrado abaixo:
int main()
{
main_display::write("Mensagem no display principal");
secondary_display::write("Mensagem no display secundário");
return 0;
}
O namespace mais comum nos programas C++ é o std (namespace relacionado à biblioteca padrão). Inclusive, ele
apareceu já nos primeiros capítulos desse livro, para utilizar a função cout:
#include <iostream>
int main()
{
std::cout << "Olá mundo!" << std::endl;
return 0;
}
No caso de você utilizar muitas funções e estruturas de dentro de um mesmo namespace, é possível utilizar using para
evitar a repetição do prefixo do namespace em questão, como no exemplo abaixo. Note, porém, que o uso de using no
escopo global é desencorajado em alguns casos, pois pode afetar parcelas de código indesejadamente. Esse ponto será
discutido novamente em capítulos posteriores desse livro.
#include <iostream>
// Sugere-se evitar `using` global
// using namespace std;
int main()
{
// `using` dentro do escopo de alguma função é preferível
using namespace std;
cout << "Ol mundo!" << endl;
return 0;
}
Visão geral sobre o processo de compilação
Conhecer o processo de compilação e linkagem do C++ é importante não apenas pelo aspecto teórico. A compreensão ajuda na solução de problemas principalmente relacionados à gerenciamento de dependências, e o reconhecimento de problemas de linkagem.
Apesar do processo ser possivelmente um pouco diferente entre diferentes sistemas operacionais, a noção geral é aproximadamente a mesma. O processo tem basicamente 3 etapas: Pré-processamento, compilação e linkagem, como ilustrado na figura abaixo. Após explicado essas etapas, esse capítulo explica brevemente sobre o processo de carregamento e execução de código compilado, e sobre o uso de bibliotecas externas.
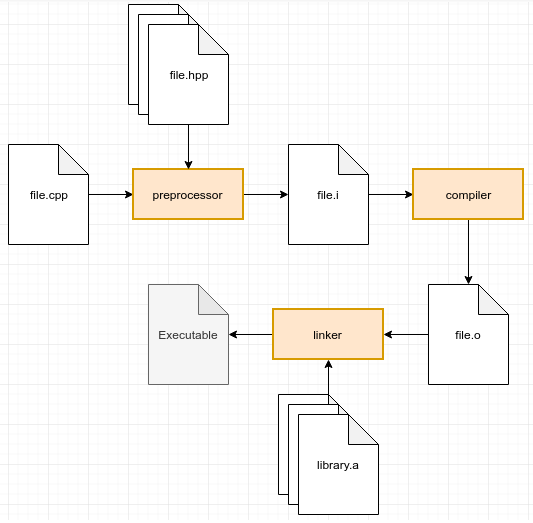
Pré-processamento
O pré-processador cuida de resolver todas as macros disponíveis no programa.
Macros são os comandos que iniciam com #, tais como #include e #define.
Para o escopo dessa seção, explicaremos o uso de quatro macros: #include, #define, #ifdef e #ifndef.
Na verdade, já usamos #include algumas vezes desde o início desse livro, mas não sabiamos exatamente seu funcionamento.
Basicamente, o que esse comando faz é buscar o conteúdo de um arquivo e inclui-lo (copia-lo) no local do #include.
Considere o seguinte exemplo: imagine que você tem um projeto com 2 arquivos, main.cpp e sum.hpp. Esse
último contém uma função auxiliar int sum(int a, int b), e você gostaria de utilizar essa função no main.cpp. Isso pode
ser feito utilizando o #include:
sum.hpp
int sum(int a, int b)
{
return a + b;
}
main.cpp
#include <iostream>
#include "sum.hpp"
int main()
{
std::cout << sum(2, 3) << std::endl;
return 0;
}
Note a diferença entre os dois includes: O primeiro utiliza <nome do arquivo>, enquanto o segundo utiliza
"nome do arquivo". A diferença é que enquanto "" busca o arquivo à ser incluído a partir da pasta corrente (ou seja,
a mesma pasta onde reside o arquivo main.cpp, nesse caso), utilizar <> faz com que o pré-processador busque o arquivo
em algumas pastas pré-determinadas, como é o caso dos diretórios padrão do sistema.
Existe um problema que, usualmente, um arquivo pode depender de outro que pode já ter sido incluído previamente.
Por exemplo, se existirem dois arquivos, a.hpp e b.hpp, onde a.hpp inclui b.hpp e vice versa, teriamos uma
recursão de inclusões impossível de resolver. Por isso, utiliza-se include guards para evitar esse problema, como no
exemplo abaixo.
Ao incluir-se o arquivo a.hpp em main.cpp, o conteúdo do arquivo a.hpp irá ser copiado. Em a.hpp,
o pré-processador irá verificar a existência da macro __A_HPP. Como ela não existe (#ifndef), ela será definida (#define),
e o conteúdo de a.hpp será totalmente copiado. Dessa forma, o arquivo b.hpp será incluído. Aqui, o mesmo procedimento
irá ocorrer, sendo definida uma variável __B_HPP. Porém, ao incluir a.hpp de dentro de b.hpp, percebe-se que, agora,
a macro __A_HPP está definida. Sendo assim, o ifndef do arquivo a.hpp percebe que não precisa processar novamente
o mesmo arquivo.
main.cpp
#include "a.hpp"
int main()
{
return 0;
}
a.hpp
#ifndef __A_HPP
#define __A_HPP
#include "b.hpp"
#endif
b.hpp
#ifndef __B_HPP
#define __B_HPP
#include "a.hpp"
#endif
O processo de inclusão de arquivos hpp é muito importante para a modularização de código.
Em C++, é comum separar a declaração das funções, classes e estruturas em arquivos .hpp, e a definição das mesmas
em arquivos .cc ou .cpp. Exceto em alguns casos específicos, como no uso de templates (será visto apenas em
capítulos mais avançados).
Erros de pré-processamento ocorrem na primeira etapa do processo de compilação. Para exemplificar, considere o exemplo
abaixo, e imagine que não existe o arquivo some_file.hpp. O erro no gcc é a.cc:1:10: fatal error: some_file.hpp: No such file or directory.
Isso significa que o arquivo não existe ou que ele existe, mas não está na pasta correta para que seja encontrado. É
muito importante que se tenha isso bem conhecido, visto que esse conhecimento auxilia na resolução de problemas no processo
de compilação.
#include "some_file.hpp"
int main()
{
return 0;
}
Macros também podem ser utilizadas como "funções" modificadas em tempo de compilação. Esse tema não vai ser discutido em profundidade nesse capítulo, e sugere-se não utilizar macros para executar esse tipo de rotina em tempo de compilação. Apenas a titulo de exemplo, seria possível definir a seguinte macro:
#include <iostream>
#define POW2(x) x*x
int main()
{
std::cout << POW2(4) << std::endl;
return 0;
}
A macro toma como parâmetro um valor x não tipado e troca o código por x*x. Para visualizar esse efeito, no gcc,
é possível compilar o arquivo acima com gcc -E main.cpp, produzindo algo semelhante ao arquivo pré-processado abaixo.
Note que a compilação não gerou um executável nesse caso, pois a opção -E orienta o compilador a parar o processo de
compilação após a etapa de pré-processamento.
// ... Outros comentários aqui ...
int main()
{
std::cout << 4*4 << std::endl;
return 0;
}
Apesar de parecer útil, a utilização de macros traz vários problemas. Por exemplo, veja o que aconteceria se chamassemos
POW2(4 + 1):
int main()
{
std::cout << 4 + 1*4 + 1 << std::endl;
return 0;
}
O resultado seria 4 + 1 * 4 + 1, ou seja, 9 (Ao invés de 25, como seria o esperado). Isso acontece por que as
macros não são equivalentes à chamadas de função. Lembre-se você está apenas criando macros que copiam valores de um
lado para outro. Uma possível solução para esse caso seria de adicionar parênteses à macro: #define POW2(x) (x)*(x),
resultando em:
int main()
{
std::cout << (4 + 1)*(4 + 1) << std::endl;
return 0;
}
De qualquer forma, orienta-se a criar funções simples do C++ e, possívelmente, utilizar constexpr em casos semelhantes
à esses.
Compilação
A próxima etapa é a de compilação, que traduz o código C++ em código assembly. Esse código, em conjunto com vários outros arquivos, são linkados, produzindo assim o executável final (ou biblioteca).
Essa é uma das partes do livro que depende de ambiente (Sistema Operacional, compilador...) para que você possa reproduzir. Apenas para fins didáticos, essa seção utilizará o Sistema Operacional Linux e o compilador GCC, invocado pela linha de comando (terminal). Considere o seguinte programa:
main.cpp
#include <iostream>
double f(double x)
{
return 3*x*x + 2*x - 1;
}
double g(double x)
{
return 3*f(x + 1.);
}
int main()
{
std::cout << f(3.) << std::endl;
std::cout << g(4.) << std::endl;
}
Pela linha de comando, utilizando GCC, é possível compilar o programa acima invocando o comando g++ main.cpp, o que
produz um executável de nome a.out. Imagine, porém, que o código do main.cpp começa a crescer, e está agora com 1000
linhas de código. Outras pessoas começaram a trabalhar no mesmo projeto. Não seria fácil manter e evoluir o programa
em um só arquivo grande com várias pessoas mexendo nele todos os dias.
Essa é uma das motivações para separar o projeto em vários arquivos. Move-se, portanto, a implementação de f e de g
para os arquivos f.hpp e g.hpp:
main.cpp
#include <iostream>
#include "f.hpp"
#include "g.hpp"
int main()
{
std::cout << f(3.) << std::endl;
std::cout << g(4.) << std::endl;
}
f.hpp
double f(double x)
{
return 3*x*x + 2*x - 1;
}
g.hpp
#include "f.hpp"
double g(double x)
{
return 3*f(x + 1.);
}
Compilar esse pequeno exemplo produz a seguinte mensagem de erro:
$ g++ main.cc
In file included from g.hpp:1,
from main.cc:3:
f.hpp:1:8: error: redefinition of ‘double f(double)’
1 | double f(double x)
| ^
In file included from main.cc:2:
f.hpp:1:8: note: ‘double f(double)’ previously defined here
1 | double f(double x)
| ^
Conforme explicado no capítulo anterior, a ausência das include guards pode ser perigoso, como é o presente caso.
Isso porque tanto main.cpp quanto g.hpp incluem f.hpp, gerando uma redefinição da função f.
Isso fica bem claro quando verificamos o output da etapa de pré-processamento isoladamente com g++ -E main.cc.
O problema pode ser resolvido, incluindo os include guards (#ifndef ... #define ... #endif), conforme código abaixo:
f.hpp
#ifndef __F_HPP
#define __F_HPP
double f(double x)
{
return 3*x*x + 2*x - 1;
}
#endif
g.hpp
#ifndef __G_HPP
#define __G_HPP
#include "f.hpp"
double g(double x)
{
return 3*f(x + 1.);
}
#endif
O novo código compila e roda normalmente, porém, não é recomendado manter as implementações das funções em headers files (arquivos .hpp),
pois a medida que o projeto cresce, o processo de compilação começará a ficar lento. Além disso, uma modificação em
qualquer header file ocasionará na recompilação de todo o projeto (Ou seja, ocasionaria em um "rebuild").
Dessa forma, é comum separar a declaração das classes e funções em arquivos hpp e a definição das mesmas em arquivos
cpp, exceto aqueles que contém templates. Nosso exemplo segue da seguinte forma:
main.cc
#include <iostream>
#include "f.hpp"
#include "g.hpp"
int main()
{
std::cout << f(3.) << std::endl;
std::cout << g(4.) << std::endl;
}
f.hpp
#ifndef __F_HPP
#define __F_HPP
double f(double x);
#endif
f.cc
#include "f.hpp"
double f(double x)
{
return 3*x*x + 2*x - 1;
}
g.hpp
#ifndef __G_HPP
#define __G_HPP
#include "f.hpp"
double g(double x);
#endif
g.cc
#include "g.hpp"
double g(double x)
{
return 3*f(x + 1.);
}
Para que os novos arquivos estejam acessiveis no momento da compilação, o processo de compilação precisa ser alterado.
Precisamos, agora, colocar todos os arquivos .cpp para que sejam compilados e linkados juntos:
g++ f.cc g.cc main.cc
Conforme notado anteriormnete, nos #includes locais, utiliza-se aspas duplas para incluir os arquivos de projeto, e
utilizamos < e > para incluir arquivos de sistema (iostream, por exempo). Arquivos incluídos com aspas duplas são
arquivos presentes da mesma pasta em relação ao arquivo que está sendo incluído. Arquivos incluidos com < e > são
buscados em uma lista pré-definida de pastas, no processo de compilação. É possível adicionar uma pasta nessa lista,
utilizando a opção de compilação -I [caminho]. De fato, não é raro encontrar projetos que acabam adicionando a pasta
corrente (local) nessa lista e utilizando apenas < e > em todos os includes. Isso pode ser uma vantagem, por exemplo,
quando estamos reestruturando o projeto e movendo arquivos. Trocando todos os includes do nosso exemplo para atuarem
com < e >, o processo de compilação se tornaria-se g++ f.cc g.cc main.cc -I...
O processo de compilação da forma como está invocado acima, na verdade inclui o processo de pré-processamento (que já
vimos) e o processo de linkagem. É possível invocar o compilador individualmente para cada arquivo arquivo .cpp e,
posteriormente, invocar o processo de linkagem separadamente. Faremos isso para fins didáticos:
g++ -c g.cc -I.
g++ -c f.cc -I.
g++ -c main.cc -I.
Esses comandos geram os arquivos chamados código objeto: g.o, f.o e main.o. Esses arquivos não são executáveis.
Para finalizar o processo de compilação, é necessário invocar (Não estou utilizando diretamente o linker nesse caso): g++ f.o g.o main.o.
Uma representação do que foi feito é mostrada abaixo:
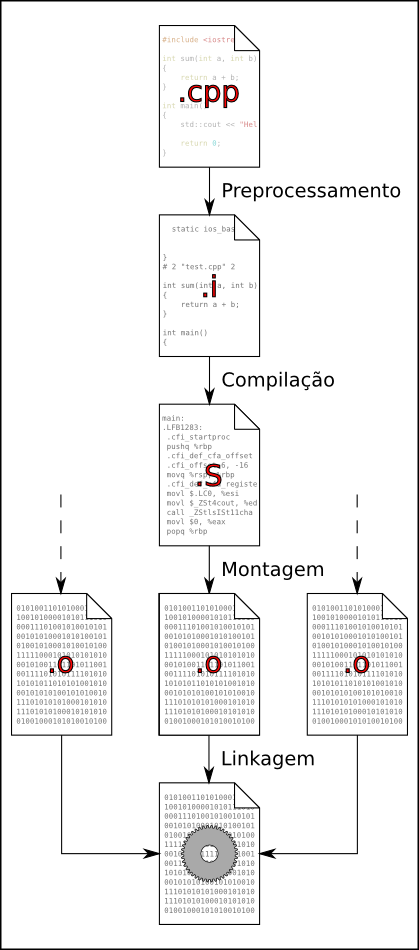
É importante ter em mente essas duas etapas como processos separados.
Erros de compilação (sintaxe e pré-processamento, por exemplo) acontecerão mesmo quando você tentar compilar o arquivo
isoladamente. Erros de linkagem (tais como undefined reference) acontecerão apenas quando você tentar compilar todos
os arquivos em conjunto ou quando você estiver executando a etapa de linkagem manualmente.
Linkagem
O processo final de geração do executável é a linkagem (não é um verbo real). Neste passo, os códigos objeto de todas as unidades de tradução envolvidas no programa são unidos em um só. Um arquivo executável pode ser obtido com o seguinte comando:
g++ f.o g.o main.o
É importante ter em mente essas etapas do processo de compilação.
Erros de compilação (sintaxe e pré-processamento) acontecerão mesmo quando você tentar compilar cada arquivo isoladamente.
Erros de linkagem (undefined reference, por exemplo) acontecerão apenas quando você tentar linkar os arquivos
para gerar um executável.
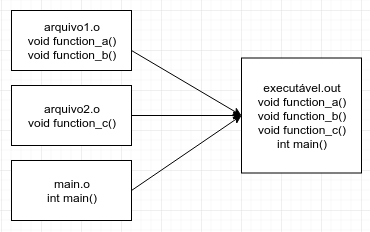
A linkagem comentada nessa seção é conhecida como linkagem estática. O código executável gerado contém todas as funções
necessárias para executa-lo, como ilustrado na imagem abaixo. Nota importante: também é usual utilizar arquivos .a ("Archive")
no processo de linkagem estática no Linux. Arquivos .a são apenas uma coleção de vários arquivos .o. Para gerar
arquivos .a, é possível utilizar o executável ar.
De forma alternativa, é possível organizar um projeto de software com funções separadas em diversos arquivos executáveis. Esses arquivos, ao invés de serem linkados estáticamente, são linkados dinamicamente, o que significa que as funções ficam espalhadas em diferentes arquivos, e buscadas pelo software em tempo de execução, ao invés de serem buscadas em tempo de compilação, como no caso da linkagem estática.
No Linux, esses arquivos possuem extensão .so ("Shared Objects"), enquanto no Windows possuem extensão .dll
(Dynamic Linked Library). O processo de geração, linkagem e carregamento de arquivos com linkagem dinâmica é diferente
no linux e no Windows.
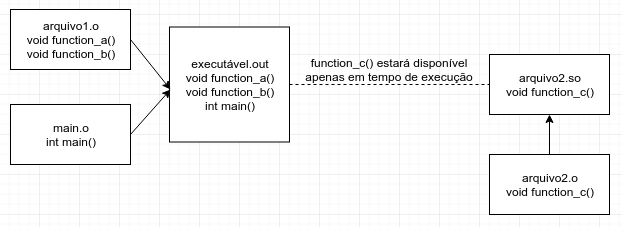
A ilustração abaixo traz uma visão geral do processo de consumo da função function_c a partir de uma linkagem
dinâmica. Nesse caso, não está sendo mostrado como o arquivo arquivo2.so foi gerado. No caso do Windows, o arquivo
arquivo2.so se chamaria arquivo2.dll.
As vantagens de utilizar uma biblioteca de linkagem estática incluem:
- Como todo o código está num só arquivo, atualizações de outras dependências não afetam (portanto, não quebram) o executável;
- Facilidade de instalação e compartilhamento do programa.
Enquanto algumas desvantagens são:
- O arquivo executável tende a ficar cada vez maior, pois precisa conter todas as funções em um só arquivo;
- Para atualizar um subconjunto de funções é necessário atualizar o arquivo executável inteiro.
Por outro lado, algumas vantagens da linkagem dinâmica incluem:
- Como o código está distribuído em diversos arquivos, atualizar um subconjunto de funções significa atualizar apenas alguns arquivos, ao invés de necessitar atualizar o código inteiro;
- As funções mais comuns podem ser aproveitadas e utilizadas em mais de um arquivo executável;
- Funções não utilizadas não precisam ser carregadas para a memória.
Finalmente, algumas desvantagens incluem:
- No caso de uso excessivo de bibliotecas dinâmicas, pode ser difícil de gerenciar as dependências;
- No caso de uma ou mais bibliotecas dinâmicas não estarem disponíveis, isso pode impossibilitar o uso de um executável.
Existem duas formas de consumir uma biblioteca dinâmica: Por meio de linkagem dinâmica em tempo de compilação (Dynamic Linking) ou por meio de carregamento dinâmico em tempo de execução (Dynamic Loading). Os dois conceitos podem ser inicialmente confusos, principalmente porque o primeiro deles possa ser confundido com o caso de linkagem estática, mas essas formas são diferentes.
Dynamic Linking faz uso de um procedimento provido pelo sistema operacional. Ao executar um programa que foi compilado dessa forma, as bibliotecas dependentes são automaticamente carregadas no início da execução do programa. Ou seja, a linkagem é feita em tempo de execução, mas é feita automaticamente.
Por outro lado Dynamic Loading significa que o programador do executável utiliza funções auxiliares para carregar
dinâmicamente cada biblioteca que queira. Por exemplo, no Linux, é possível utilizar a função dlopen para carregar
um arquivo .so. Ou seja, a linkagem é feita em tempo de execução, mas é feita manualmente.
Gerenciamento de pacotes
Como visto, o processo de compilação passa por diferentes estágios até a criação de um arquivo executável. A separação
de funções, variáveis, constantes e outras entidades em artefatos (arquivos .hpp, .a, .so etc...) possibilita o
compartilhamento de código.
Por exemplo, se um programador A cria um módulo de um software escrito em C++ que é capaz de criar uma janela (interface gráfica), esse mesmo módulo pode ser utilizado por um programador B em outro projeto, desde que o programador A tenha utilizado alguma das ferramentas apresentadas nessa seção.
Uma possibilidade, seria de o programador A ter criado uma biblioteca estática e prover esses arquivos binários e os arquivos
.hpp associados para o programador B. Dessa forma, o programador A pode criar um pacote, contendo a biblioteca que
pode ser enviado ao programador B, e que contém todos os arquivos necessários para que o programador B possa criar
seus programas.
Alguns exemplos de bibliotecas incluem: Qt (criação de programas com interface gráfica), Boost (contém várias funções auxiliares), GoogleTest (automatização de testes), entre muitas outras.
O problema é que, em geral, para gerenciar e utilizar essas bibliotecas, normalmente o programador precisa ter algum
conhecimento específico da biblioteca (normalmente obtém-se o conhecimento por meio da leitura dos manuais de cada uma
delas). Uma alternativa interessante para utilizar as bibliotecas é o uso do software CMake, abordado em outra seção
desse livro.
Um segundo problema que ocorre é que é possível que as bibliotecas tenham sido criadas utilizando outras bibliotecas. Essa sequência de dependências pode ocasionar em problemas de compilação e execução que são dificeis de se lidar. Daí vem a necessidade de um gerenciador de pacotes. Gerenciadores de pacote são ferramentas que auxiliam no processo de download, automatizam o processo de instalação, e cuidam das dependências entre os pacotes e o seu programa.
O intuito dessa seção não é fazer propaganda nem ensinar uma ferramenta específica. Ao invés disso, apenas apontam-se os problemas e algumas possíveis ferramentas que podem ser utilizadas para resolve-los, que incluem:
- Conan
- Conda
- apt - Advanced Package Tool
- vcpkg
Introdução à biblioteca padrão do C++
A biblioteca padrão do C++ provê algumas funcionalidades básicas para desenvolvimento de software, como strings, vetores, listas, tuplas, além de funções utilitárias para lidar com gerenciamento de memória, I/O, sistema de arquivos, threads, entre outras. Esse capítulo apresenta uma breve introdução, mostrando algumas das funcionalidades disponíveis na biblioteca. Não é necessário baixar nem configurar nada, para utilizar a biblioteca padrão.
String
Strings são estruturas de dados que representam sequências de elementos, sendo o mais comum a sequência de caracteres
(char). A biblioteca padrão provê uma série de funcionalidades para lidar com strings, a partir do header <string>.
É importante notar que sequências de caracteres dentro de aspas duplas (") não são do tipo string em C++. Considere
o exemplo abaixo:
#include <string>
int main()
{
auto word = "Exemplo"; // *Não* é do tipo std::string
auto other_word = std::string("Outro Exemplo"); // É do tipo std::string
// (A partir de C++14)
using namespace std::string_literals;
auto yet_another_word = "Mais um exemplo"s; // É do tipo std::string
return 0;
}
word não é do tipo std::string. Isso por que C++ não possui string como tipo primitivo da linguagem. Ao invés
disso, word possui tipo const char[8], que representa um "array de 8 elementos do tipo char" (7 caracteres na
palavra "Exemplo" + 1 caracter de fim de texto, representado por \0).
Por outro lado, other_word e yet_another_word são do tipo std::string.
A vantagem de utilizar std::string ao invés de const char[], é que ela provê várias funções e métodos de manipulação
e extração de dados para strings. Por exemplo, é possível concatenar duas std::strings utilizando o operador +, mas
não é possível fazer o mesmo com const char[]:
#include <string>
#include <iostream>
int main()
{
using namespace std::string_literals;
auto string1 = "Hello "s;
auto string2 = "World"s;
auto string3 = string1 + string2;
std::cout << string3 << "\n"; // Mostra "Hello World"
// O código abaixo produz um erro de compilação, pois não é possível
// somar duas variáveis do tipo `const char*`:
// auto var1 = "Hello ";
// auto var2 = "World";
// auto var3 = var1 + var2; // ERRO de compilação
return 0;
}
A partir desse momento, utiliza-se a palavra "string" para denotar std::string.
É possível converter strings de/para os tipos primitivos int e float, por meio de funções auxiliares. Esse tipo de
conversão é especialmente útil para traduzir inputs de usuário em dados numéricos. Exemplo:
#include <string>
#include <iostream>
int main()
{
using namespace std::string_literals;
auto value1 = "12"s;
auto value2 = "7"s;
auto string3 = value1 + value2; // Produz "127" (com tipo string)
auto value3 = std::stoi(value1) + std::stoi(value2); // Produz 19 (com tipo int)
std::cout << string3 << ", " << value3 << "\n"; // Mostra 127, 19
return 0;
}
Para converter strings para floats, pode-se utilizar std::stof. Para converter int e float para strings, pode-se
utilizar std::to_string. Uma lista extensa de funcionalidades para std::sring está disponível aqui.
Input/Output (Entrada/Saída)
O termo I/O se refere aos dispositivos de Entrada (Input) e Saída (Output). Essa seção traz
uma introdução para trabalhar com a leitura de dados do usuário pelo terminal (CMD) e a escrita de dados em terminal e
em arquivos de texto.
A forma mais comum de escrever dados no terminal, em C++, é a partir de std::cout ("Character Output"), e é a
forma como vêm sendo escritos os exemplos desse livro desde os primeiros capítulos.
Para utilizar o std::cout, é necessário incluir o header <iostream>, como mostra o exemplo abaixo.
#include <iostream>
int main()
{
std::cout << "Hello World!\n"; // Escreve "Hello World!" e pula uma linha (\n)
return 0;
}
A sintaxe é diferente em relação às chamadas de função normalmente utilizada. Note que ao invés de std::cout("texto"),
escreve-se std::cout << "texto";. Isso se dá pela forma como std::cout foi implementado. Na verdade, ele é um
objeto que possui um operator<<, e não uma função. Essa informação é apenas a título de curiosidade, e não afeta o uso
do std::cout.
Não é necessário converter os dados para string para utilizar o std::cout. Ele consegue lidar com dados de outros
tipos, como int e float. Basta escrever std::cout << my_int;, sendo my_int uma variável do tipo
int, por exemplo.
É possível ler dados do usuário a partir de std::cin ("Character input"), como no exemplo abaixo.
Os dados lidos podem ser de qualquer tipo primitivo ou string. Os dados podem ser separados por quebra de linha ou por
espaço.
#include <iostream>
#include <string>
int main()
{
using namespace std::string_literals;
std::cout << "Digite os 3 dados:\n";
auto my_int = 0;
auto my_float = 0.;
auto my_string = ""s;
std::cin >> my_int >> my_float >> my_string;
std::cout << "Você digitou: " << my_int << ", " << my_float << ", " << my_string << "\n";
return 0;
}
Note que até agora todos os programas apresentados guardavam as suas variáveis em memória. Isso significa que, ao
reiniciar o programa, todos os cálculos com as variáveis são perdidos. Uma das formas de persistir (guardar) dados em
disco é utilizando o fstream, como no exemplo abaixo. Claro que isso é uma forma bastante primitiva de persistir
dados. É importante lembrar que existem softwares de banco de dados e bibliotecas de gerenciamento de arquivos
mais robustas. Mesmo assim, é interessante conhecer a biblioteca padrão, por ser uma alternativa válida para a
persistência de dados em algumas situações. É importante apenas manter em mente que não é a única e nem necessariamente
a melhor ferramenta para resolver qualquer problema.
#include <iostream>
#include <fstream>
#include <string>
int main() {
using namespace std::string_literals;
auto filename = "arquivo.txt"s;
auto file_stream = std::fstream(filename, std::ios::out);
if (!file_stream.is_open()) {
std::cout << "Failed to open " << filename << '\n';
return -1;
}
auto variable = 1.234;
file_stream << "Conteúdo do arquivo!\n"s;
file_stream << variable;
return 0;
}
O exemplo acima abre um arquivo chamado arquivo.txt em modo de saída (std::ios::out). O programa verifica se foi
possível abrir o arquivo e, caso negativo, gera uma mensagem e sai do programa com um código de erro (return -1).
Uma vez aberto, escreve-se uma string de exemplo,
e uma variável do tipo float. Note que o arquivo não é explicitamente fechado (close). Isso por que o
fstream garante que o arquivo será fechado ao fim do escopo de vida do mesmo. Dessa forma, não é necessário fechar
o arquivo explicitamente.
O código capaz de gerar um programa que faz a leitura do mesmo arquivo é mostrado abaixo. Na verdade, essa é apenas uma
das formas de fazer a leitura dos dados de um arquivo. Também é possível ler o conteúdo de um arquivo caracter por
caracter. Para isso, poderia-se utilizar o método file_stream.get(l);, com l sendo do tipo char. Cada forma de
leitura tem suas vantagens e desvantagens, e seu uso vai depender do problema que se está tentando resolver.
#include <iostream>
#include <fstream>
#include <string>
int main() {
using namespace std::string_literals;
auto filename = "arquivo.txt"s;
auto file_stream = std::fstream(filename, std::ios::in);
if (!file_stream.is_open()) {
std::cout << "Failed to open " << filename << '\n';
return -1;
}
auto line = ""s;
auto i = 1;
while(!file_stream.eof()) {
getline(file_stream, line);
std::cout << "Linha " << i << ": " << line << '\n';
i += 1;
}
return 0;
}
Estudo de Caso: Input de dados para juizes online
Existem vários sites na internet para exercitar a prática de programação e algoritmos. Esses sites são conhecidos como "juizes online" como, por exemplo, UVa e Spoj. Nesses sites, é comum encontrar problemas com um formato bastante específico para os inputs dos dados dos desafios. Essa subseção traz um breve tutorial para iniciantes em C++, em relação a como poderia-se fazer a leitura dos dados para esses tipos de problema.
Para o exercício, considere o problema PRIME1 do Spoj, copiado (e traduzido) abaixo, para referência:
Peter deseja gerar todos os números primos para seu sistema. Você deve ajuda-lo. Gere todos os números primos entre dois números dados.
Entrada
A entrada inicia com um número
t, que representa o número de testes (t <= 10). Cada uma dastpróximas linhas contém dois números,men, separados por espaços.Saída
Para cada caso de teste, escreva na tela todos os primos
pondem <= p <= n. Cada número primo deve ser escrito em uma linha diferente. Casos de teste devem ser separados por uma linha em branco.Exemplo
Entrada:
2
1 10
3 5Saída:
2
3
5
73
5
O objetivo aqui não é resolver o problema completamente, apenas implementar a leitura dos dados. A entrada de
dados segue um padrão bem definido, conforme o exemplo acima. A primeira linha contém apenas um número, que deve ser lido na
variável t. As t linhas seguintes devem conter pares de números (m, n).
Conforme visto, é possível fazer a leitura dos dados a partir do std::cin. Utiliza-se, então, essa forma para fazer
a leitura da variável t:
#include <iostream>
int main() {
auto t = 0;
std::cin >> t;
std::cout << "CASOS DE TESTE: " << t << '\n';
return 0;
}
A seguir, para fazer a leitura dos pares m e n, é possível utilizar um for com um contador de i = 0 até t.
Enquanto esse contador não chegar no valor de t, lê-se um novo par de valores. Assume-se que os valores serão dois
números válidos (Não é feita nenhuma verificação sobre os valores).
#include <iostream>
int main() {
auto t = 0;
std::cin >> t;
std::cout << "CASOS DE TESTE: " << t << '\n';
for (auto i = 0; i < t; ++i) {
auto n = 0;
auto m = 0;
std::cin >> n >> m;
std::cout << "Processando dados: (" << n << ", " << m << ")\n";
// ... resto do código ...
}
return 0;
}
Uma curiosidade interessante é que, no linux, é possível redirecionar o conteúdo de um arquivo texto, de forma que ele
sirva de entrada para um programa. Por exemplo, digamos que você compile o arquivo acima e gere um executável chamado
programa. Ao invés de executar esse programa e digitar as entradas dos dados manualmente, é possível criar um arquivo
(por exemplo, input.txt) cujo conteúdo é conforme dado abaixo, e redirecionar o conteúdo desse arquivo para a entrada
do programa programa, da seguinte forma: ./programa < input.txt.
2
1 10
3 5
O resultado da execução é dado abaixo. Essa é uma forma rápida de manter arquivos de teste para problemas de maratona de programação e juizes online.
$ ./programa < input.txt
CASOS DE TESTE: 2
Processando dados: (1, 10)
Processando dados: (3, 5)
Array
Um std::array é um container com um número pré-definido de dados de um certo tipo. O tipo e o tamanho do array devem
ser conhecidos em tempo de compilação. Isso significa que você não pode aumentar o tamanho do array a partir de um input
de usuário, por exemplo.
Uma das vantagens em utilizar std::array ao invés de arrays "crus" (por exemplo, int[3]), é que você pode passar std::array
como argumentos de funções, e retorna-los sem complicações. Além disso, std::array possui métodos de acesso à dados do array e algumas
operações auxiliares sobre ele.
Para declarar e definir um std::array, basta escolher um tipo (e.g. int, float, etc...) e um tamanho, conforme
exemplo abaixo:
#include <array>
#include <iostream>
int main()
{
// Inicializa um array com 3 elementos. Os valores são '1', '2' e '3'.
auto my_arr = std::array<int, 3>{1, 2, 3};
for (int i = 0; i < my_arr.size(); ++i) {
std::cout << "my_arr[" << i << "] = " << my_arr[i] << "\n";
}
// Preenche todo o array com o valor '42'
my_arr.fill(42);
for (int i = 0; i < my_arr.size(); ++i) {
std::cout << "my_arr[" << i << "] = " << my_arr[i] << "\n";
}
return 0;
}
Vector
std::vector permite o programador a criar um vetor com um tamanho dinâmico de elementos. Em outras palavras, é uma estrutura que permite inserir e remover elementos de uma lista em tempo de execução. No exemplo abaixo, A linha 3 inclui o header <vector>, para que seja possível utilizar a estrutura de dados std::vector. A linha 17 cria uma instancia de um vector. Os elementos desse vector serão do tipo Point. Ou seja, não será possível colocar inteiros, doubles, ou variáveis de nenhum outro tipo nesse vector. O vector foi inicializado sem elementos e, nas linhas 19 e 20, dois elementos são adicionados utilizando o método push_back.
#include <iostream>
#include <cmath>
#include <vector>
struct Point {
double x;
double y;
};
double calculate_distance(Point p1, Point p2)
{
return sqrt(pow(p1.x - p2.x, 2) + pow(p1.y - p2.y, 2));
}
int main()
{
std::vector<Point> points;
points.push_back(Point{1.2, 3.4});
points.push_back(Point{4.5, 5.6});
std::cout << "A distância entre os pontos é " << calculate_distance(points[0], points[1]) << std::endl;
return 0;
}
A linha 22 usa a função calculate_distance, mas passa como parâmetros os elementos cujos índices são 0 e 1 no vector. Tenha cuidado para nunca acessar o vector com indices que não foram populados. Para saber a quantidade de elementos de um vector, é possível utilizar o método size(). Para remover o último elemento adicionado, é possível utilizar o método pop_back().
Map
std::map é a primeira estrutura de dados que será abordada nesse livro. Pense em uma estrutura de dados como uma struct que guarda informações para consultas, e que algumas estruturas organizam os dados de uma maneira específica para que as consultas sejam mais rápidas.
Toda estrutura de dados é diferente uma da outra, e mais apta para resolver um problema do que outro, por exemplo, todas as coisas que são feitas com std::map podem ser feitas com std::vector (estrutura exibida posteriormente), mas dependendo do que seja, fazer com std::map pode ser mais fácil e simples, ou mais difícil e complicado.
std::map é uma estrutura de dados que mapeia um dado à outro. Ele é formado por vários pares de chave (key) e valor (value), depois de montado, dada uma chave, a estrutura deverá retornar qual é o valor único que foi atribuído àquela chave.
Considere a seguinte tabela de dados como exemplo:
| Nome | Idade |
|---|---|
"Alice" | 20 |
"Bruno" | 30 |
"Carol" | 40 |
"Júlia" | 50 |
"Pedro" | 50 |
Vamos criar um std::map vazio, adicionar cada linha dessa tabela, e então, dado um nome, quermos ter certeza que a estrutura vai retornar a idade correta.
#include <iostream>
#include <map>
#include <string>
int main()
{
// An empty map
std::map<std::string, int> ages;
// Adding the data
ages["Alice"] = 20;
ages["Bruno"] = 30;
ages["Carol"] = 40;
ages["Júlia"] = 50;
ages["Pedro"] = 50;
// Outputs: "Alice tem 20 anos."
std::cout << "Alice tem " << ages["Alice"] << " anos.\n";
// Outputs: "Pedro tem 50 anos."
std::cout << "Pedro tem " << ages["Pedro"] << " anos.\n";
ages["Pedro"] = 51;
// "Pedro agora tem 51 anos."
std::cout << "Pedro agora tem " << ages["Pedro"] << " anos.\n";
return 0;
}
Para declarar essa estrutura, é necessário explicitar os tipos de dados das chaves e dos valores, com a seguinte sintaxe:
std::map<K, V>
Isso representa um map que possui chaves do tipo K e valores do tipo V, no exemplo acima o mapa foi declarado da seguinte forma:
std::map<std::string, int> ages;
Nesse caso, K=std::string e V=int, então std::map<std::string, int> mapeia pares de string e inteiros.
Também é possível iterar em todos os elementos do map:
#include <iostream>
#include <map>
int main()
{
std::map<int, bool> my_map;
my_map[3] = true;
my_map[7] = false;
for (auto const& [key, value] : my_map) {
std::cout << key << ": " << value << std::endl;
}
std::cout << my_map[3] << std::endl;
std::cout << my_map.at(3) << std::endl;
// With [], values will be added if they are not present
std::cout << my_map[9] << std::endl;
// With .at(), will throw exception if value not present
std::cout << my_map.at(8) << std::endl;
return 0;
}
Set
std::function & lambda
Introdução à biblioteca padrão do C++
A biblioteca padrão do C++ provê algumas funcionalidades básicas para desenvolvimento de software, como strings, vetores, listas, tuplas, além de funções utilitárias para lidar com gerenciamento de memória, I/O, sistema de arquivos, threads, entre outras. Esse capítulo apresenta uma breve introdução, mostrando algumas das funcionalidades disponíveis na biblioteca. Não é necessário baixar nem configurar nada, para utilizar a biblioteca padrão.
Classes e Objetos
A base da programação orientada a objetos são os objetos. No contexto de C++ objetos são instâncias de classes, classes são abstrações que contém a descrição de quais atributos e métodos um objeto possui e atributos são variáveis internas de uma classe. Métodos são funções membro (member functions) de uma classe. Exemplo:
#include <iostream>
class Cachorro {
public:
void latir()
{
std::cout << "Au! Au!!\n";
}
};
int main()
{
Cachorro bidu;
bidu.latir();
return 0;
}
No código acima, Cachorro é uma classe. O objeto bidu é uma instância da classe Cachorro. Como Cachorro possui o método latir, é possível invoca-lo por meio de bidu.latir().
Métodos podem ser públicos (public), protegidos (protected) ou privados (private). Métodos e atributos privados não podem ser invocados fora do escopo da classe. Métodos e atributos protegidos podem ser invocados apenas no escopo da classe ou de classes filhas (Hierarquia de classes é tema do próximo capítulo). Métodos e atributos públicos podem ser acessados de dentro ou de fora do escopo da classe.
Sugere-se manter os atributos de uma classe como membros privados ou protegidos, e acessa-los apenas através de métodos, a fim de esconder os detalhes do objeto, e expondo apenas alguns métodos públicos. À isso da-se o nome de encapsulamento.
O construtor de uma classe é um método especial que possui o nome igual ao nome da classe e não possui retorno. O construtor da classe serve para inicializar os atributos internos e deixa-la em um estado utilizavel. Exemplo:
#include <iostream>
#include <string>
class Cachorro {
public:
Cachorro(std::string const& nome)
: nome(nome)
{}
void latir()
{
std::cout << "Au! Au!! Eu sou o " << this->nome << '\n';
}
private:
std::string nome;
};
int main()
{
Cachorro bidu{"Bidu"};
bidu.latir();
return 0;
}
No exemplo acima Cachorro(std::string const& nome) é o construtor da classe Cachorro. Note que o construtor possui um parâmetro do tipo std::string. Dessa forma, para construir um Cachorro agora é necessário passar alguma string como parâmetro. Isso está sendo feito na linha Cachorro bidu{"Bidu"};. Essa linha está construindo uma instância da classe Cachorro de nome bidu e cuja variável interna nome terá o valor Bidu.
Note a sintaxe de construção do Cachorro:
Cachorro(std::string const& nome)
: nome(nome)
{}
Note que o : nome(nome) está ANTES da abertura do escopo do corpo do construtor, ou seja, antes das chaves {}. Essa sintaxe possibilita que a construção do objeto seja feita antes de entrar no corpo do construtor. Isso se chama lista de inicialização (initializer list). Alternativamente poderia-se escrever
Cachorro(std::string const& nome)
{
this->nome = nome;
}
Onde this é uma variável especial que é um ponteiro para a própria instância da classe em questão. O uso de this é
opcional dentro do escopo da classe, de forma que é possível se referir a atributos da mesma diretamente.
O código acima altera o valor do membro nome para o valor contido na variável local nome. Diferente do código
anterior, this->nome primeiro é inicializado com valor vazio, para somente ser alterado dentro do corpo do construtor
de Cachorro.
Assim como qualquer outra variável em C++, instâncias de classes podem ser alocadas na pilha ou na heap. Para alocar uma instância na pilha, basta seguir o procedimento dos exemplos anteriores, copiado abaixo apenas para facilitar a leitura:
int main()
{
Cachorro bidu{"Bidu"}; // <--- Alocado na pilha
bidu.latir();
return 0;
}
Por outro lado, para alocar na heap deve-se fazer uso da palavra reservada new, conforme exemplo abaixo. Tal qual explicado em capítulos anteriores toda memória alocada na heap deve ser desalocada pelo programador. No caso de variáveis inicializadas com new é necessário utilizar o delete.
int main()
{
auto* bidu = new Cachorro{"Bidu"}; // <--- Alocado na heap
bidu->latir();
delete bidu;
return 0;
}
Note que a sintaxe de acesso ao método latir mudou. Isso ocorre por que no exemplo acima bidu é um ponteiro para uma instância de Cachorro. Dessa forma o acesso ao método latir é feito com -> ao invés de .. Alternativamente poderia-se de-referenciar o ponteiro. Porém, a sintaxe ficaria bastante esquisita e não é sugerida:
int main()
{
auto* bidu = new Cachorro{"Bidu"}; // <--- Alocado na heap
(*bidu).latir();
delete bidu;
return 0;
}
O objeto bidu será destruído no momento que delete é invocado. No caso da variável em pilha o objeto é destruido no momento que sair do escopo. Em ambos os casos é possível invocar um código especial de destrução do objeto. Esse código fica no método destrutor da classe que possui nome equivalente ao do construtor, porém, com o simbolo ~ como prefixo. O destrutor é útil quando é necessário liberar algum recurso obtido em algum momento da vida do objeto. Exemplo:
#include <iostream>
#include <string>
class Cachorro {
public:
Cachorro(std::string const& nome)
: nome(nome)
{}
~Cachorro()
{
// Código executado no momento que o cachorro está sendo destruido
std::cout << "Estou sendo destruido!!\n";
}
void latir()
{
std::cout << "Au! Au!! Eu sou o " << this->nome << '\n';
}
private:
std::string nome;
};
int main()
{
Cachorro bidu{"Bidu"};
bidu.latir();
return 0;
}
Esses são os conceitos básicos de orientação a objetos necessários para iniciar um contato com o tema em linguagem C++. Os capítulos posteriores vão entrar em outros conceitos fundamentais e de extrema importância para a programação orientada a objetos. Por fim, é importante mencionar que programação orientada a objetos é um paradigma muito interessante e pode ajudar na solução de vários problemas. Porém, tenha sempre em mente que não é o único paradigma de programação e que nem sempre é o melhor para qualquer situação.
Herança e Polimorfismo
Chama-se herança o mecanismo que permite a uma classe herdar membros (métodos e atributos) de outra classe. Tal mecanismo permite reaproveitar código comum entre classes filhas. Porém, uma vantagem ainda mais importante é a possibilidade de criar interfaces.
A sintaxe para a criação de uma classe base é mostrada no exemplo abaixo. A classe ClasseFilha estende a classe
ClasseMae. Em outras palavras, a classe ClasseFilha é formada por todos os seus atributos e métodos mais todos
os da classe ClasseMae.
#include <iostream>
#include <string>
class ClasseMae {
public:
ClasseMae(int atributo_1)
: atributo_1(atributo_1)
, atributo_privado('z')
{}
void metodo_1()
{
std::cout << "O metodo 1 foi invocado!\n";
}
protected:
int atributo_1;
private:
char atributo_privado;
};
class ClasseFilha : public ClasseMae {
public:
ClasseFilha(int atributo_1, double atributo_2)
: ClasseMae(atributo_1)
, atributo_2(atributo_2)
{}
void metodo_2()
{
std::cout << "O metodo 2 foi invocado!";
}
private:
double atributo_2;
};
int main()
{
ClasseMae objeto_1{1};
objeto_1.metodo_1();
ClasseFilha objeto_2{1, 2.2};
objeto_2.metodo_1();
objeto_2.metodo_2();
return 0;
}
O exemplo é extremamente simples, e serve apenas para ilustrar a sintaxe de herança em C++ e iniciar um contato do leitor
sobre esses aspectos da linguagem. Note que ambas as instâncias objeto_1 e objeto_2 podem invocar o método
metodo_1, e apenas a instância da classe ClasseFilha pode invocar o método metodo_2. Isso ocorre porque objeto_2
é uma instância da classe ClasseFilha, que possui tanto os métodos e atributos de ClasseMae quanto aqueles
referentes à própria classe ClasseFilha.
O construtor da classe ClasseFilha precisa invocar o construtor da classe mãe (ClasseMae) de forma a construir
corretamente a mesma. A sintaxe para a construção da classe mãe é mostrada no exemplo acima. A classe ClasseFilha possui
um construtor que contém uma lista de inicialização onde o construtor da classe mãe é invocado. Caso a
classe mãe não tivesse um construtor definido (se estivesse sendo utilizado o construtor padrão), não seria
necessário invoca-lo explicitamente como no exemplo acima.
Além disso, é possível reescrever um método da classe mãe, de forma a alterar seu funcionamento, na classe filha.
Considere o exemplo abaixo. A classe ClasseMae possui agora um método publico virtual chamado metodo_virtual, e a
classe ClasseFilha possui um método de mesmo nome com o modificador override. Esse modificador é opcional e está
disponível apenas em versões mais atuais da linguagem. É uma boa prática de programação adiciona-lo, a fim de manter uma
consistência entre classe base e classe filha.
#include <iostream>
class ClasseMae {
public:
virtual void metodo_virtual()
{
std::cout << "Comportamento da classe mae.\n";
}
};
class ClasseFilha : public ClasseMae {
public:
void metodo_virtual() override
{
std::cout << "Outro comportamento!!\n";
}
};
void executar_algoritmo(ClasseMae& objeto)
{
// ... Imagine um algoritmo aqui ...
objeto.metodo_virtual();
}
int main()
{
ClasseMae objeto_1;
executar_algoritmo(objeto_1);
ClasseFilha objeto_2;
executar_algoritmo(objeto_2);
return 0;
}
Note que a função executar_algoritmo recebe como parâmetro uma referência para um objeto da classe ClasseMae. Ainda assim,
na função main, uma instância da classe ClasseFilha é enviada como parâmetro. Sempre é possível utilizar instâncias de
classes filhas como parâmetros para referências ou ponteiros para sua classe mãe. O método executar_algoritmo vai se
comportar de forma diferente, dependendo do tipo de objeto sendo recebido como parâmetro. Sendo mais específico, para o
caso do exemplo acima a primeira chamada de executar_algoritmo(objeto_1) resultará no texto escrito
Comportamento da classe mae., enquanto a segunda chamada executar_algoritmo(objeto_2) resultará no texto
Outro comportamento!!. Essa característica se chama Polimorfismo.
Um aspecto muito importante de se ter em mente é que no caso da ausência do virtual na classe mãe, o polimorfismo do
exemplo não acontecerá conforme esperado. Basicamente a ausência de virtual ignora a funcionalidade que possibilita a
invocação correta do método da classe filha, quando a mesma é passada por parâmetro como uma classe base, como no
exemplo. Em outras palavras, a remoção de virtual (e por consequência a remoção de override) no exemplo resultaria
que as duas chamadas retornarem o texto Comportamento da classe mae..
Uma classe pode possuir métodos virtuais sem implementação, como no próximo exemplo. Classes com pelo menos um método
virtual sem implementação não podem ser instanciadas. Ou seja, não é possível construir um objeto cujo tipo seja uma
classe com métodos sem implementação. Classes cujos métodos são todos virtuais e sem implementação são chamadas
interfaces. Classes que contenham pelo menos um método com implementação são chamadas classes abstratas. Portanto, no
exemplo abaixo, a classe ClasseInterface é uma interface.
#include <iostream>
class ClasseInterface {
public:
virtual void metodo_a() = 0;
};
class ClasseConcreta_A : public ClasseInterface {
public:
void metodo_a() override {
std::cout << "Metodo A invocado pela classe concreta A!\n";
}
};
class ClasseConcreta_B : public ClasseInterface {
public:
void metodo_a() override {
std::cout << "Metodo A invocado pela classe concreta B!\n";
}
};
void executar_algoritmo(ClasseInterface& objeto)
{
objeto.metodo_a();
}
int main()
{
ClasseConcreta_A objeto_1;
executar_algoritmo(objeto_1);
ClasseConcreta_B objeto_2;
executar_algoritmo(objeto_2);
return 0;
}
Um exemplo prático do uso de polimorfismo é mostrado a seguir. Imagine que tenhamos um sistema com vários elementos gráficos: retangulos, circulos, triangulos... Cada estrutura é representada por uma classe com as informações pertinentes. Por exemplo:
class Retangulo {
private:
Vetor posicao;
double largura;
double altura;
};
class Circulo {
private:
Vetor posicao;
double raio;
};
Para desenhar um conjunto de elementos gráficos na tela poderíamos ter uma interface em comum para eles, e determinar um método para cada classe desenhar-se:
class ElementoGrafico {
public:
virtual void desenhar() const = 0;
};
class Retangulo : ElementoGrafico {
public:
void desenhar() const override { /*...*/ }
/*...*/
};
Por fim, no programa principal é possível ter um vetor de ElementoGrafico, e considerando que cada um deles sabe se
desenhar, o código final fica:
void desenhar_tela(std::vector<std::unique_ptr<ElementoGrafico>> const& elementos)
{
for (auto const& elemento : elementos) {
elemento->desenhar();
}
}
O código completo é apresentado abaixo. O código apresentado é apenas ilustrativo, visto que ele não desenha nada de fato na tela, ele apenas escreve textos no terminal.
#include <iostream>
#include <vector>
#include <memory>
struct Vetor {
double x;
double y;
};
class ElementoGrafico {
public:
virtual void desenhar() const = 0;
};
class Retangulo : public ElementoGrafico {
public:
void desenhar() const override
{
std::cout << "Desenhando o retangulo!\n";
}
private:
Vetor posicao;
double largura;
double altura;
};
class Circulo : public ElementoGrafico {
public:
void desenhar() const override
{
std::cout << "Desenhando o circulo!\n";
}
private:
Vetor posicao;
double raio;
};
void desenhar_tela(std::vector<std::unique_ptr<ElementoGrafico>> const& elementos)
{
for (auto const& elemento : elementos) {
elemento->desenhar();
}
}
int main()
{
auto elementos = std::vector<std::unique_ptr<ElementoGrafico>>{};
elementos.push_back(std::make_unique<Circulo>());
elementos.push_back(std::make_unique<Retangulo>());
desenhar_tela(elementos);
}
Utiliza-se um std::vector de unique_ptr neste exemplo pois não é possível criar um std::vector<ElementoGrafico> (já que
trata-se de uma interface) e nem um std::vector<ElementoGrafico&> (já que não é possível criar um vector de referências).
A última alternativa seria std::vector<ElementoGrafico*>, que funcionaria normalmente, exceto pelo fato de que seria
necessário fazer o gerenciamento da memória de alguma forma. Para delegar esse gerenciamento, decide-se utilizar os
smart pointers (nesse caso unique_ptr) de forma a simplificar o código final.
FAQ - Frequent Asked Questions
Perguntas que surgem recorrentemente no canal C/C++ Brasil são movidas para esse FAQ, de forma a centralizar a informação e minimizar o número de discussões repetidas.
Qual o melhor editor/IDE pra programar em C++?
De forma geral, aquele que você se sente mais confortável. Se você está começando e ainda não sabe qual é o mais confortável pra você, abaixo deixamos uma lista de sugestões. Sugerimos que iniciantes não usem o Code::Blocks por ser um projeto abandonado.
- KDevelop
- (Windows) Visual Studio Community Edition
- CLion Student Edition
Se você não gosta de IDEs (Integrated Development Environment), existem bons editores de texto para programar em C++:
- Vim
- NeoVIM
- Kate
Essa lista é baseada no que as pessoas do canal usam (Se você usa algo que não está na lista, fique à vontade para adicionar). Ao atualizar a lista por favor mantenha os projetos open-source no topo, em qualquer ordem.